San Francisco Crime Classification
Project Overview
The use of machine learning and artificial intelligence for detection and prevention of crimes has increased dramatically over the past few decades. Law enforcement agencies have access to large volumes of crime data stretching back decades, and they are looking for ways that this data can be leveraged for prediction of crime patterns and types.
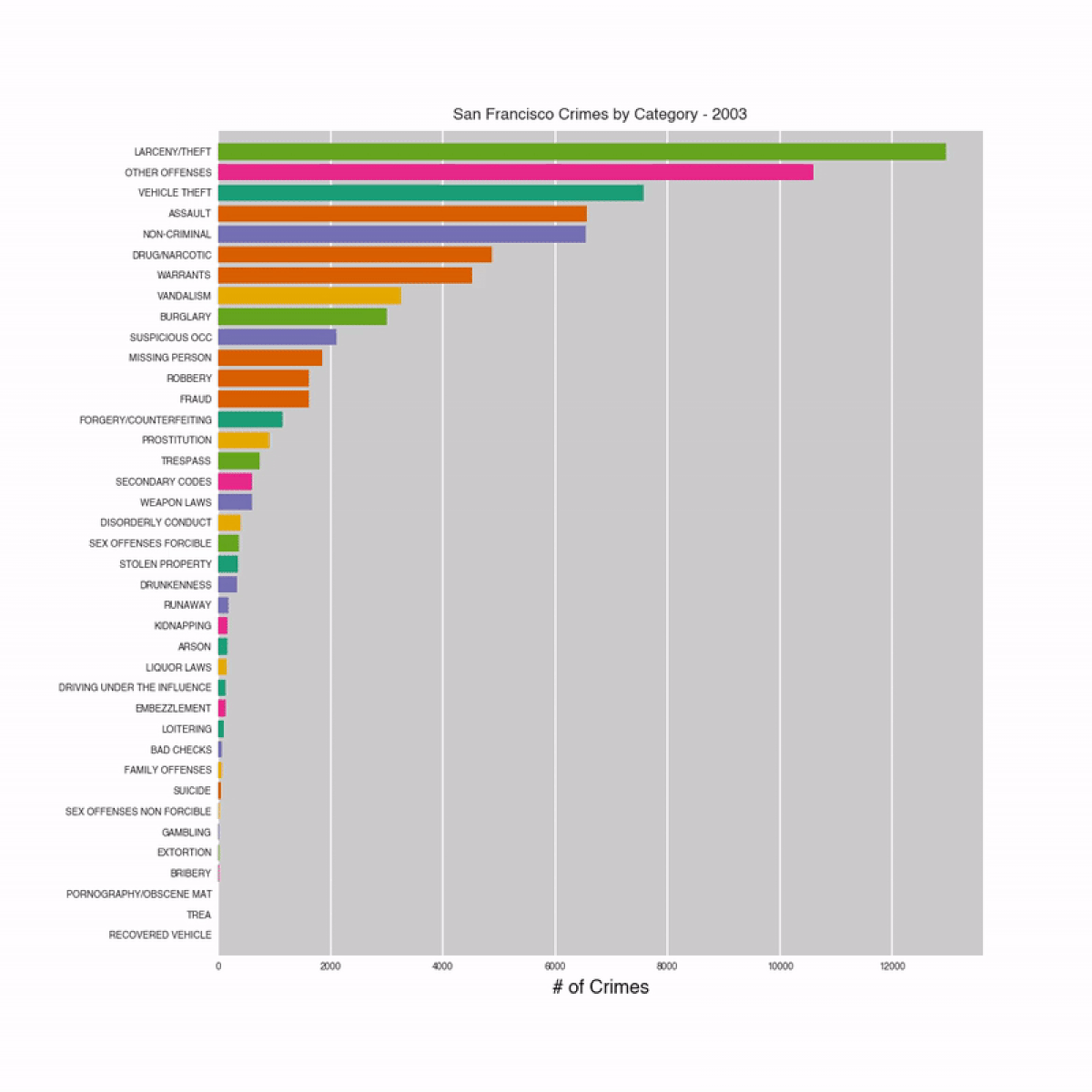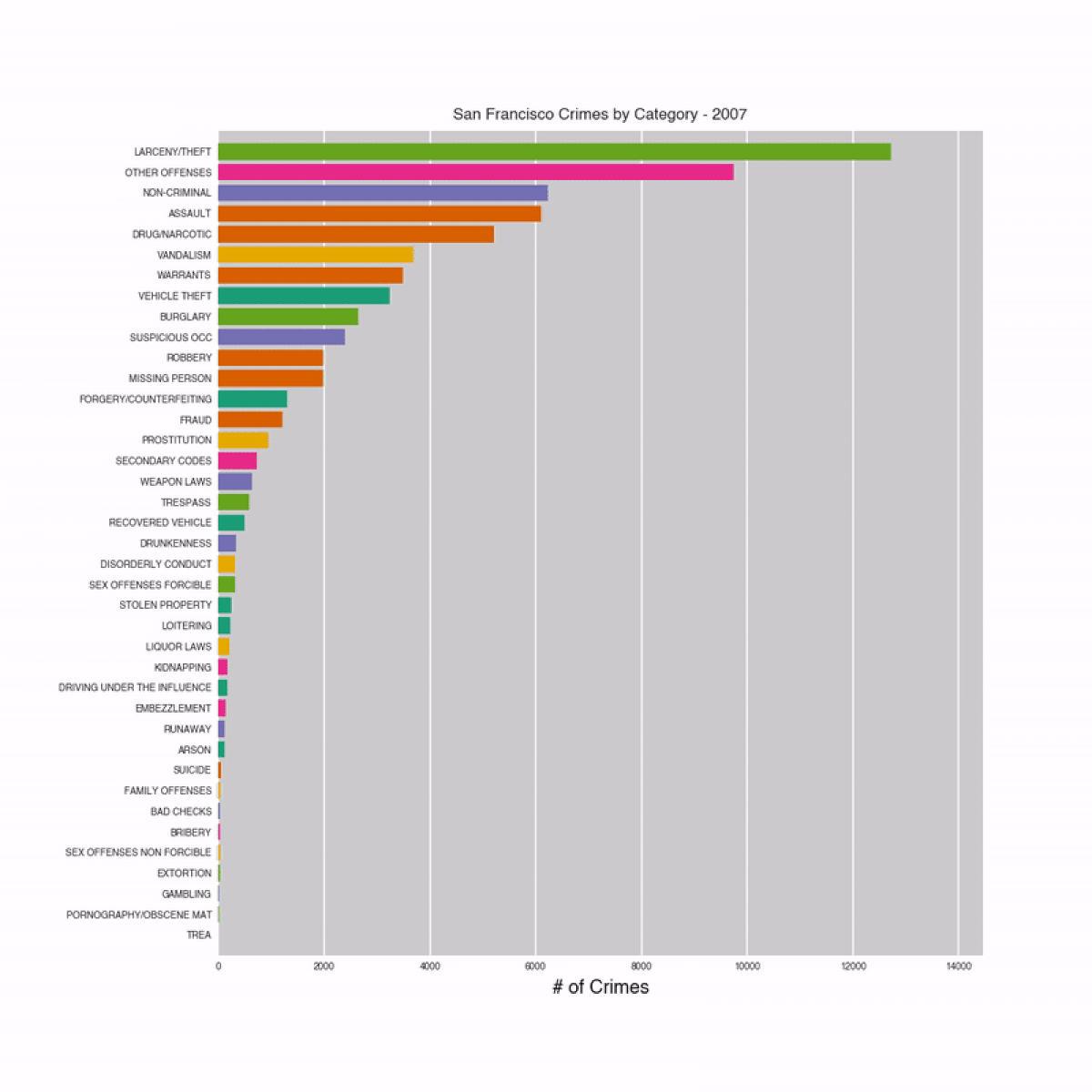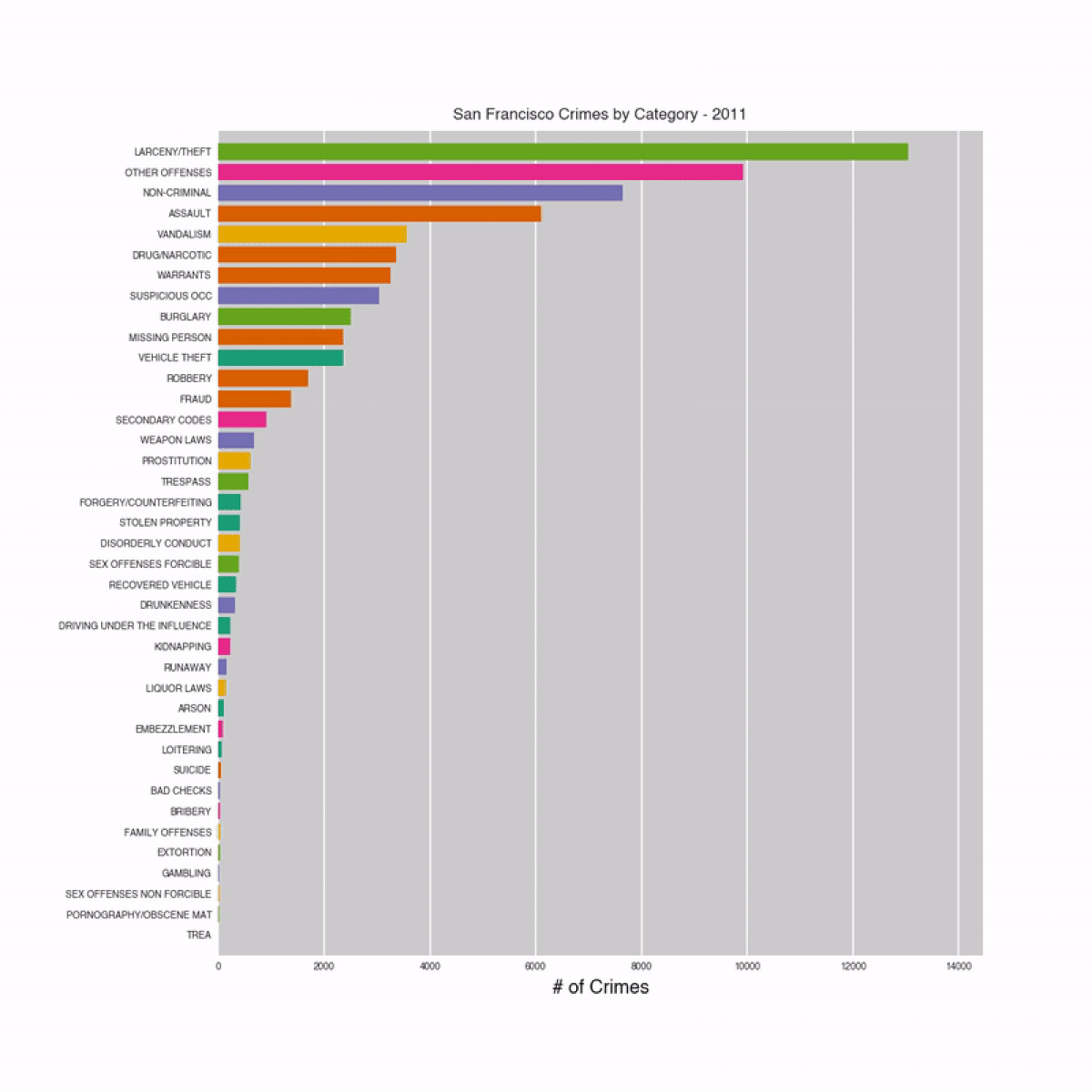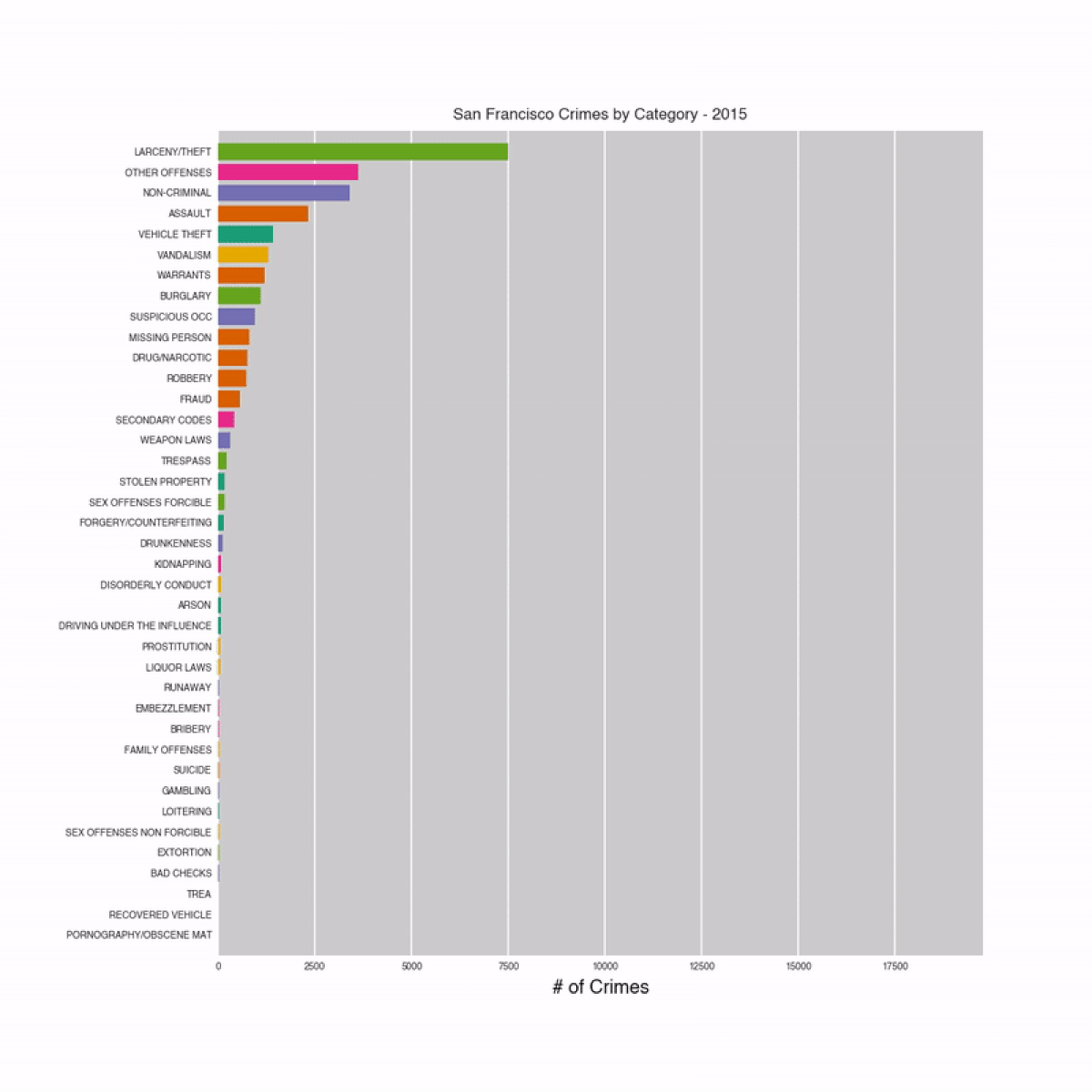
This project focuses on the use of historical crime data in San Francisco to predict the category of a crime event given only information about the event’s time and location. The project is based on the San Francisco Crime Classification Kaggle Competition, which concluded in 2016. The dataset, provided by SF OpenData, includes nearly 12 years of crime reports from the San Francisco metropolitan area collected between 2003 and 2015 and can be downloaded from the competition website.
This article presents an end-to-end approach for tackling this problem, including initial data evaluation, preprocessing, modeling, and creating an ensemble using our best models. Code for this project can be found in the following GitHub repo: https://github.com/dontmindifiduda/sf-crime.
The problem can be summarized as follows:
Given the time and location for a crime event, predict the category of crime that occurred.
Evaluation Metric
Test predictions were evaluated using multiclass logarithmic loss. The formula for calculation of multiclass logarithmic loss is as follows:

In this formula, N is the number of crimes observed in the test dataset, M is the number of category (class) labels, yᵢⱼ is 1 if observation i is in class j and 0 otherwise, and pᵢⱼ is the predicted probability that observation belongs to class j. A perfect classifier would produce a multiclass logarithmic loss of 0, and our model should be built to score as low as possible using this metric.
Analysis
Data Exploration
The training dataset (train.csv) included the following features:
- Dates — timestamp indicating when the crime incident was reported
- Category — crime incident category
- Descript — description of the crime incident
- DayOfWeek — day of the week
- PdDistrict — Police Department District name
- Resolution — crime incident resolution
- Address — approximate street address of the crime incident
- X — longitude where the crime incident was reported
- Y — latitude where the crime incident was reported
The test dataset (test.csv) included these features as well, with the exception of Category, Descript and Resolution. Additionally, the test dataset includes a unique Id feature assigned to each observed crime incident that will be used to create the final submission file.
The sample submission file (sampleSubmission.csv) provides an example of the required format for crime category predictions based on the test dataset.
The provided data originated from the SFPD Crime Incident Reporting system, and it includes crimes that occurred between 1/1/2003 and 5/13/2015. Training and testing incident data were collected from alternating weeks. Odd rows were sequestered into the test dataset, leaving the remaining even rows to serve as the training dataset.
An evaluation of the raw training and test datasets respective sizes indicated the following:

Missing/Duplicate Values
No missing values were identified in the training or test datasets.
The training dataset included 2,323 duplicate rows. It is unclear whether these values represent reporting errors or multiple instances of the same crime occurring at the same time and location. Regardless, these values were removed from the training data since they provide redundant information. The test dataset contained no duplicate rows.
Erroneous Values
Erroneous X/Y coordinate pairs of (-120.5, 90.0) were observed in 67 rows in the training dataset and in 76 rows in the test dataset. This location is in Antarctica, while all remaining coordinate pairs in the dataset lie within the boundaries of San Francisco. Each of these observed coordinate pairs was replaced with the mean X and Y coordinate of the PdDistrict in which the crime incident occurred.
Extraneous Features
Since the Descript and Resolution features are not found in the test dataset, these features will not prove useful for developing a predictive model. These features were removed from the training dataset during preprocessing.
Prediction Approach
Our goal is to develop a model that correctly identifies the Category of each crime in the test dataset. This type of problem is considered a multiclass classification problem. In this instance, a total of 39 classes of crime category are represented in the training data.
Our model should assign a predicted probability to each of the 39 possible classes of crime category for each test observation, rather than simply predicting a single class. Selecting a single class is the equivalent of assigning a probability of 1 to that class and a probability of 0 to all other classes. If this approach is taken and the selected class is incorrect, the evaluation metric will assign the maximum penalty per observation. Using class probabilities as opposed to selecting a single class decreases the penalty we receive from the evaluation metric in the event that our prediction is incorrect.

Data Preprocessing & Feature Engineering
Temporal Features
Using the Dates feature, the following temporal features were generated:
- Year
- Month
- Day
- Hour
- Minute
- Special Time (binary feature; 1 if the reported crime incident time ends in :00 or :30, 0 otherwise)
- Weekend (binary feature; 1 if the reported crime incident occurred on Saturday or Sunday, 0 otherwise)
- Night (binary feature; 1 if the reported crime incident occurred between 6 PM and 6 AM; 0 otherwise)
Address Embeddings
The address provided for each crime incident was presented in two formats:
- Intersection — OAK ST / LAGUNA ST
- Block — 100 Block of BRODERICK ST
A binary feature was created for each observation indicating whether the crime incident occurred at an intersection or a block. Additionally, embeddings for Address values were generated using Word2Vec. Original Address values were dropped following creation of embeddings.
Embeddings are vectors of numerical values that are used to represent strings of text. Word embeddings include a vector of numerical values for each individual word appearing in a string of text. These numerical values are used to translate information about the text into a format that our machine learning algorithms can understand and process. For a detailed explanation of what word embeddings are and how they work, check out this article.
Transformations & Aggregations
The following transformations and aggregations were used to generate new features using the X and Y coordinate of each crime event:
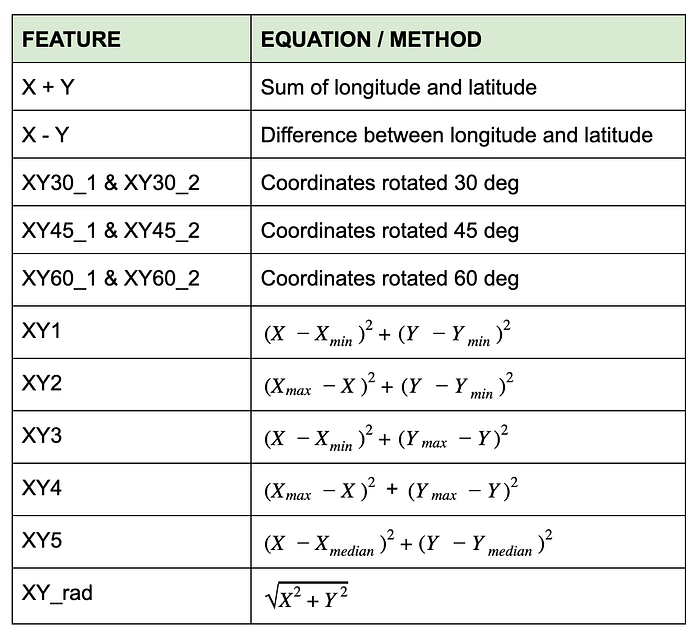
Many of these features were produced by trial and error, and the rationale behind their effectiveness is unclear. For example, taking the sum or difference of latitude and longitude values does not produce a meaningful value to a human. The same can be said of XY1 — XY5, which are generated by taking the sum of the squared coordinates using various types and combinations of scaling. However, inclusion of these features provided slight improvements to model performance, so they were maintained.
Coordinate plane rotations of geospatial data may seem arbitrary, but they can help with decision tree splitting in tree-based models.
Principal Components Analysis (# of components = 2) was also used to rotate the X/Y coordinate plane, generating two additional features (XYpca1, XYpca2). While PCA is typically used for dimensionality reduction, it can also be used as an additional means of rotating the coordinate space.
Clustering
Clustering is an unsupervised machine learning method that groups data points together into clusters with shared characteristics. Successful clustering means that data points are more similar to other data points within their cluster than they are to data points from other clusters. This technique is considered unsupervised since it is performed using only the dataset itself and not using labeled examples.
Several clustering algorithms were evaluated for feature generation based on assigned cluster, including k-means clustering, OPTICS clustering, and gaussian mixture models. Ultimately a gaussian mixture model was implemented since this clustering algorithm provided the best blend of speed and feature importance. Various cluster sizes were tested, and a size of 150 was found to produce the most impactful feature. A gaussian mixture model was produced using the training data, and a cluster was assigned to each crime incident and stored as a new feature, XYcluster.
Log Odds
Log odds are simply an alternative way of expressing probability. Using probability, log odds can be calculated as follows:
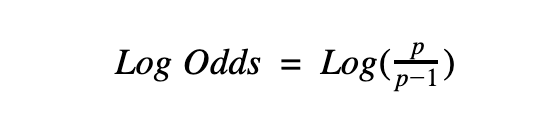
In the equation above, p represents the probability of an event happening.
To calculate default log odds, data were first grouped by Category. The probability of each Category occurring was calculated by counting the number of occurrences for each Category in the training dataset and dividing it by the total number of training observations. These probabilities were used to calculate log odds, creating a vector with a length of 39 (the number of crime Category classes). This vector was repeated and concatenated to itself vertically, forming an array with a width of 39 and a length equal to the total number of observations in the training dataset.
These values represent the “default” log odds to be used if there are very few observations of a unique item within the target feature. For example, if we set a threshold that a unique address must occur in the dataset at least 5 times in order to calculate meaningful log odds based on grouping by address, addresses with < 5 observations will be assigned these default log odds values.
Next, log odds for each crime Category were calculated by grouping data based on the following features:
- Address
- Hour
- DayOfWeek
The training dataset was grouped based on Category and each target feature. Unique items were identified in each target feature, and log odds were calculated for each unique item in the target feature based on crime Category. Log odds values for each crime category were appended to the data set. For each target feature, a threshold of 2 observations was set, meaning that feature values with only 1 observation were assigned default log odds values based on crime category. This really only applied to Address values that appear only once in the training data.
Each of these sets of log odds were then appended to the test dataset based on the observed value of each target feature. The test dataset includes a few address values that do not appear in the training dataset. Default log odds calculated based on crime category were used for these addresses.
Categorical Encoding
Following feature generation, our dataset contained a mixture of numerical and categorical features. Numerical features are features that are represented by continuous numerical values, while categorical features are represented by a discrete number of categories, or classes. For example, a feature such as DayOfWeek has a discrete number of possible values (Sunday — Saturday).
Modeling algorithms require numerical input in order to function. Categorical data is often represented as a string of text that provides a qualitative description of the information it represents. The process of converting a string representation of a variable to a numerical value is known as encoding.
There are several different strategies for encoding categorical values. One of the most common methods is label encoding. Label encoding is the process of assigning a single integer value to each unique class that a variable may represent. For example, the DayOfWeek variable can be one of seven possible values. During label encoding, each DayOfWeek value is assigned an integer value of 0–6 based on its class.
The following categorical features were label encoded prior to model training:
- DayOfWeek
- PdDistrict
- Intersection
- Special Time
- XYcluster
Target Variable Encoding
Category data were processed differently depending on the algorithm used to construct the model. For tree-based algorithms, the Category feature was label encoded, while for neural networks, the Category feature was one hot encoded. One hot encoding requires creation of an individual column for each possible class of a categorical feature. For each observation, a value of 1 is assigned to the column of the identified class while a value of 0 is assigned to all other class columns. Training and testing data were combined during the encoding process to improve the preprocessing efficiency.
Feature Scaling
Data input to a neural network or other algorithms that use gradient descent as an optimization technique must be scaled prior to training. Two common methods of feature scaling are standardization and normalization. Normalization, also known as min-max scaling, shifts and rescales all data values so they are between 0 and 1. Standardization recenters the mean of each feature to zero, and the data are scaled such that the distribution of points for each feature has a standard deviation of 1.
Choosing between whether or not to standardize or normalize data depends on how the data is distributed. One of the benefits of standardization is that it handles outliers better than normalization. Each feature scaling method was tested, and standardization was found to produce better results. Standardization was performed using StandardScaler from scikit-learn.
Standardization of input data is not required for tree-based algorithms. These algorithms are not sensitive to feature scale since each individual tree is formed by splitting on a single feature. This preprocessing step was only completed for the input to the neural network.
Model Development
A total of 123 features were generated during data preprocessing, and these features were used to construct our predictive models. Our team tried several different approaches when developing predictive models. Our solution included a blended ensemble of tree-based models and a fully connected neural network.
Tree-Based Algorithms
The following tree-based algorithms were used to construct models using our preprocessed training data:
- LightGBM
- CatBoost
- Random Forest
Each of these algorithms performed comparatively when evaluated using the competition metric. Hyperparameters for each tree-based algorithm were optimized using GridSearchCV from scikit-learn.
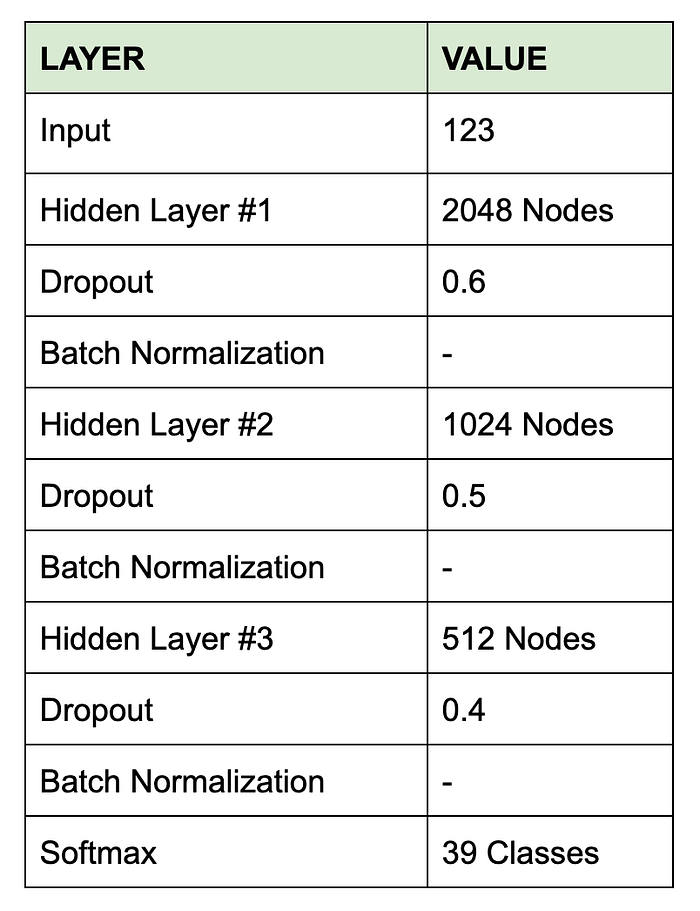
Neural Network
In addition to our tree-based models, we developed a fully connected neural network to predict crime category. The neural network was trained with a batch size of 256 and a learning rate of 0.001 using Adam optimization. The structure of the neural network is shown in the table below:
Cross Validation
Each model was trained using 5-fold cross validation. Validation splits were created using StratifiedKFold from scikit-learn to try and maintain consistent class representation across each validation fold. During training, each model was used to create a set of out-of-fold predictions on the training data. The model produced by each fold was then used to generate predictions. These predictions were averaged across the fold to produce a final set of predictions. Out-of-fold training predictions were also stored for creation of a stacked ensemble.
Ensemble
Ensembling refers to the practice of combining the results from multiple learning algorithms to improve predictive performance. By combining the prediction results from multiple models, a more resilient final model can be constructed that generalizes better to test data than each of its component models.
There are several different approaches to model ensembling, including blending, stacking, model averaging, and many others. A stacked ensemble was selected for this project.
A stacked ensemble requires a set of predictions from each model for both the training and test data. Typically, it is best to generate predictions for training data by predicting out-of-fold data during cross validation. This way the model does not have to predict the results of data that it was trained upon, which can result in overfitting.
Training data predictions from each model were concatenated into a single training dataset, while test predictions were concatenated to form a test dataset. A secondary classifier (LightGBM) was then trained on the concatenated training predictions. The resulting model was used to generate predictions using the concatenated test predictions as input. The resulting predictions were submitted to Kaggle for evaluation.
Results
Multiclass log loss for the predictions produced by each model as well as the final stacked ensemble are shown in the table below:
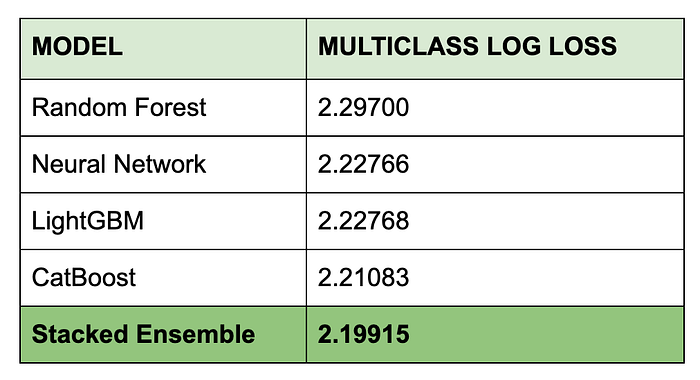
These results demonstrate the usefulness of stacking models to produce improved prediction accuracy. If this solution had been submitted for the original Kaggle competition, it would have been good enough for 39th place overall.
Final Notes
This project was completed as part of a mock Kaggle competition organized by the PGH Data Science Meetup group for participants based in and around Pittsburgh, PA. Organizers selected a previously-completed Kaggle competition (San Francisco Crime Classification) and organized group members into teams to try and develop solutions for the problem.
The project work presented here was prepared by myself, Steve Estes, George Jiang, and Mo Kaiser. Our team (Team 4) placed 2nd overall. A copy of our presentation that was delivered at the end of the competition can be found here. Code for our solution can be found here: https://github.com/dontmindifiduda/sf-crime.
