Urban Environmental Audio Classification Using Mel Spectrograms
This article provides a basic introduction to audio classification using deep learning. We will build a Convolutional Neural Network (CNN) that takes Mel spectrograms generated from the UrbanSound8K dataset as input and attempts to classify each audio file based on human annotations of the files. Code for this article can be found in this Git repository.
Audio Classification
Audio classification describes the process of using machine learning algorithms to analyze raw audio data and identify the type of audio data that is present. In most applications, this is done using annotated data with target classes selected by human listeners.
There is a wide range of different applications for audio classification. A great deal of research has been completed for speech recognition and development of speech-to-text systems. Audio classification has also been used for automated music categorization and recommendation engines. Classification of environmental sounds has been proposed for identification of specific species of birds and whales. Additionally, monitoring of environmental sounds in urban environments has been proposed to aid in law enforcement through identification of sounds that may be associated with crime (i.e. gunshots) or unauthorized construction (i.e. jackhammers).
Problem Approach
Currently, state-of-the-art methods for audio classification approach the problem as an image classification task. This may seem surprising, but given the advancements that have been made with image classification over the past couple of decades, it makes logical sense that these methods should be transferred into other domains. In this article, we will discuss how images are generated from audio data and how they can be processed and manipulated for classification tasks.
UrbanSound8K: Dataset Background
We will be using the UrbanSound8K dataset for this article to provide a background on some of the fundamental techniques used for environmental audio classification. This dataset was developed by Justin Salamon, Christopher Jacoby and Juan Pablo Bello, and it is frequently used to evaluate and benchmark audio classification techniques. Here is a description of the dataset taken directly from its companion website:
This dataset contains 8732 labeled sound excerpts (<=4s) of urban sounds from 10 classes: air_conditioner, car_horn, children_playing, dog_bark, drilling, engine_idling, gun_shot, jackhammer, siren, and street_music.
Sound excerpts were originally extracted using environmental field recordings uploaded to www.freesound.org. You can find more information on how the excerpts were assembled in the researchers’ original paper, A Dataset and Taxonomy for Urban Sound Research.
The audio segments come pre-sorted into 10 separate folds for training. On the companion website, the researchers strongly suggest the following:
- Don’t rearrange the data (use the 10 folds that have been provided)
- Evaluate on all 10 folds (don’t provide single-fold evaluation results)
We will be following each of these suggestions in this example.
Metadata
The UrbanSound8K dataset comes with a metadata CSV file that includes class labels for each sound file as well as a few other pieces of information. Let’s take a look at the first five rows of this file:

Both numerical and textual class labels are provided. Individual sound files were extracted from larger field recordings, and the metadata file provides the start and stop time of the extracted piece of the original field recording.
A salience feature is also included in the metadata. Salience refers to the prominence, or noticeability, of the sound within the recording. The two states indicated by this binary feature are foreground (1) and background (2).
Audio Signal Analysis
Librosa
We will be using a Python package called librosa for our audio analysis. This package is designed for analysis of music and audio files and is very useful for extraction of audio features and development of informative visualizations. You can find more information about librosa, including tutorials, in the package documentation and reference manual.
Time Domain Representation
Audio signals can be represented in one of two domains: the time domain or the frequency domain. Sound representation in the time domain is what we typically see when we load an audio file into an audio editor such as Audacity. At a physical level, sound can be defined as propagation of longitudinal pressure waves through a medium, such as air. These pressure waves vary in terms of density and amplitude. Amplitude refers to the displacement of air particles from a baseline point, and it serves as a measure of the loudness, or volume, of an audio signal at a given time. A higher amplitude indicates greater displacement of air particles and thus a louder sound volume. The figure below provides an illustration of amplitude using some basic sine waves.
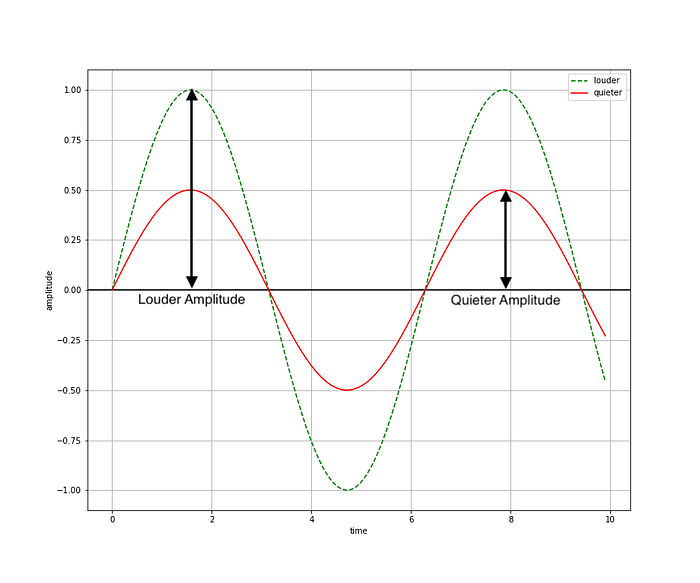
This figure is a representation of sound within the time domain, where we are visualizing the change in the sound amplitude over time. When represented in the time domain, an actual audio signal looks much messier than these simple representations. This example is a random 5-ms segment extracted from one of the UrbanSound8K files (100263–2–0–117.wav, a sample of children playing from fold5):

Frequency Domain Representation
Alternatively, sound can be represented in the frequency domain. In this representation, we are able to look over a range of frequencies and identify the proportion of the signal that corresponds to each frequency.
Converting sound data from the time domain to the frequency domain can be accomplished using a Fourier transform function. A Fourier transform function breaks a time domain signal into a series of component frequencies represented by sine waves. This set of component frequencies represents the spectrum of an audio signal. We can visualize how the spectrum of an audio signal varies over time using a type of plot known as a spectrogram.
To generate a spectrogram, we will need to look at the Fourier transform of several individual segments of the audio event to see how the spectrum varies over time. To do this, we need to use a Short-time Fourier transform (STFT). This transform calculates the spectrum over a discrete time window, then shifts this window forward until the spectrum has been calculated for the full audio event. The width of the window that is used and the amount of overlap between subsequent windows are examples of parameters that need to be defined when using an STFT to develop a spectrogram. Essentially, spectrogram is a heatmap showing the intensity of sound (represented in decibels) at each frequency band over a series of time steps. A linear spectrogram of our example file is shown below:

The spectrogram illustrates that a majority of the sonic information is transferred via lower frequencies. Higher frequency bands demonstrate lower sound intensity. To focus the visualization on the area that contains the most sonic information, we can use a log scale on the y-axis of the spectrogram to create a log spectrogram:

Mel Scale
Human perception of sound differs slightly from its physical representation. This is especially noticeable when humans are asked to identify the spacing between two separate pitches. Beginning at a frequency around 500 Hz, the perceived interval between two pitches decreases as frequency increases. For example, tones with frequencies of 1,000 Hz and 1,500 Hz sound further apart from one another than tones with frequencies of 5,000 Hz and 5,500 Hz even though each of these frequency pairs are separated by the same frequency distance. This trend becomes more pronounced as frequency increases, meaning that humans have an easier time distinguishing between nearby tones at lower frequencies than at higher frequencies.
The Mel scale was developed in an effort to try and scale frequency data in a way which more closely resembles the way humans perceive sound. The Mel scale is divided into units called mels, and a reference frequency of 1,000 Hz 40 dB above a listener’s threshold is defined as 1,000 mels. Below 500 Hz, the number of mels associated with a tone very closely correspond to its frequency. Above 500 Hz, the number of mels between pitches perceived as “evenly spaced” increases as frequency increases.
By using the Mel scale for frequency data and representing the audio power data on a log scale by converting it to decibels, we can generate an image known as a Mel spectrogram. Since audio classification tasks are based on human annotations and Mel spectrograms are designed to provide a representation of audio data that more closely matches human perception, researchers have found that Mel spectrograms are very useful for classification of audio events. A Mel spectrogram created using our example file is shown below:

Additional features that are also useful for audio classification can be extracted from Mel spectrograms. Mel Frequency Cepstral Coefficients (MFCCs) are a powerful audio feature that can be generated by performing a discrete cosine transform on Mel spectrogram data. The transformed data provides a more compact representation of the audio data than the Mel spectrogram and has proven to be very useful for audio classification.
For this article, we will be utilizing Mel spectrograms in lieu of MFCCs. Future work may include a comparison of the two techniques for audio classification as well as development of a model architecture that takes both sets of features as input.
File Processing
We will be developing a CNN to classify our sound files using their respective Mel spectrograms. In order to do this, we will first have to convert each WAV file into a Mel spectrogram. While generating image files is useful for creating quick visualizations, it is processing- and memory-intensive to convert each WAV file into an image file that is saved to disk. Instead, we will stop short of generating an image file and instead will save each spectrogram as a zipped archive of Numpy arrays using Numpy’s savez() function. This function generates a *.npz file that is lightweight and can easily be accessed later during training and testing of the model.
When converting each WAV file into a Mel spectrogram, we need to make sure that each of our images is the same size. To determine the size that should be used, we can look at the duration of each file. This information can be obtained using the start and end times provided in the metadata:
metadata['duration'] = metadata['end'] - metadata['start']
metadata['duration'].describe()
This summary indicates that the majority of our files are 4 seconds long, but there are some files of shorter duration included in our dataset.
In the future, if we decide to use employ transfer learning using a pre-trained model we may need to revisit our image sizing. Many pre-trained models are designed to accept a set image size as input, so our image size may need to be modified. Since we are not using a pre-trained model at this time, we will stick with our current image size.
Additional parameters that we will need to select for generation of Mel spectrograms include:
- Sampling Rate (sr)
- Number of Mels (n_mels)
- Length of Discrete Fourier Transformation Window (n_ft)
- Hop Length (hop_length)
- Minimum Frequency (fmin)
The sampling rate refers to refers to the number of samples of audio collected per second during recording. This value is automatically extracted when audio data is loaded into librosa. Additionally, the dataset creators identify the sampling rate as 22050 Hz for all files contained within the dataset.
The number of Mels refers to the number Mel bands, or “bins”, that our Mel scale will be broken up into. We will be using a value of 128 for this parameter since this value is included in the librosa documentation, but other values (i.e. 64, 512, etc.) have also been implemented successfully for audio classification tasks.
The length of the discrete Fourier transformation window describes the size of the window that will be used when performing each discrete Fourier transformation across the audio signal, while the hop length describes how much this window is to be shifted along the audio signal during each step of STFT processing. Selection of window size can be fairly complex, and research papers have been written focusing solely on this element of Mel spectrogram generation. We will be using librosa’s default values of 2048 for window length and 512 for hop length.
The minimum frequency describes the low frequency cutoff point that will be used when generating our Mel spectrograms. We will be using a value of 20 Hz for this parameter since this value represents the bottom of the audible frequency spectrum for most humans.
Cross Validation
Our model will be trained using 10-fold cross validation. We will be using the folds as they have been defined by the dataset creators. This means that we will be creating ten separate models. Each model will be trained using data from nine folds, while the remaining fold data will be withheld from the training data. We will refer to this fold as our hold-out, or validation, fold. The trained model will be used to predict the class of each sample included in the hold-out fold.
Predictions of the hold-out fold classes are known as out-of-fold predictions. We will collect the out-of-fold predictions from each of our ten models and use these to assess our overall model performance.
Model Architecture
We will be building a CNN using PyTorch, and we will use this CNN to predict the class of each audio sample. To build the CNN, we will need to define some constituent components, including Dataset objects and blocks containing the layers of the neural network. Combining multiple layers into blocks is not necessary, but it makes the resulting code much easier to understand and reduces repetition.
A block diagram illustrating the model architecture we will be using is shown below. We will go into more detail on the individual components of the model in the sections that follow.

Datasets
Prior to training, we will load all of our data into Dataset objects. We will create a child training Dataset class (TrainDataset) that inherits properties from the PyTorch Dataset class imported from torch.utils.data. PyTorch supports two different types of Dataset: Map-Style and Iterable-Style.
A map-style Dataset maps data to unique keys/indices, while an iterable-style Dataset creates an iterable object for a set of data samples. Iterable-style Datasets are more appropriate for situations where random selection of data from its source is either not achievable or would be computationally expensive. This type of Dataset may be useful for training models using data collected from a remote server or database. Since this circumstance does not apply to our audio classification problem, we will be using a map-style Dataset.
We will extend our custom TrainDataset class to include the capacity to convert our Mel spectrograms from numpy arrays to Image objects and to apply transforms to each file. Transforms can be used to augment our training data through basic image transformations. We will include only limited transforms for this example, applying only a RandomHorizontalFlip with a probability of 0.5 and conversion to a tensor. Sample code for our custom TrainDataset class is shown below:
class TrainDataset(Dataset):
def __init__(self, melspecs, labels, transforms):
super().__init__()
self.melspecs = melspecs
self.labels = labels
self.transforms = transforms def __len__(self):
return len(self.melspecs) def __getitem__(self, idx):
image = Image.fromarray(self.melspecs[idx], mode='RGB')
image = self.transforms(image).div_(255)
label = self.labels[idx] return image, label
Typically, we would load all of our data into a training Dataset and create a separate validation Dataset by performing a random split directly on the Dataset object using the SubsetRandomSampler class provided in torch.utils.data. Since our data has already been split into separate folds, we will use our TrainDataset class to define both our training and validation (out-of-fold) Datasets.
Convolutional Blocks
We will define a convolutional block class (ConvBlock) that we can repeat multiple times using different numbers of input and output channels. Each convolutional block class includes the following layers:
- 2D Convolutional Layer
- Batch Normalization
- ReLU Activation
- 2D Convolutional Layer
- ReLU Activation
- Dropout (Probability = 0.5)
- 2D Average Pooling
Our model includes a series of four convolutional blocks in series, each containing two 2D convolutional layers with a kernel size equal to 3, stride equal to 1, and padding equal to 1. The first block takes a 3-channel image as an input and outputs 64 channels. Each sequential block doubles the number of channels, creating an output from the 4th block containing 512 channels. Increasing the number of channels as the depth of the network increases allows the model to learn increasingly complex features.
Fully Connected Layers
The fully connected portion of our model takes the output the fourth convolutional block as input. Data passes through the following fully connected layers:
- Dropout (Probability = 0.4)
- Linear Layer (512 input features, 128 output features)
- PReLU Activation
- Batch Normalization
- Dropout (Probability = 0.2)
- Linear Layer (128 input features, 10 output features)
Dropout is included to improve model generalization, while batch normalization is included to stabilize the learning process, speeding up the training process.
PReLU Activation
PReLU, or Parametric ReLU, activation is applied to the output of our first linear layer. A typical ReLU activation function receives model weights as input. If the input weights are positive, the ReLU function returns them directly as output. If the input weights are 0.0 or less, the ReLU function produces 0.0 values as output.
PReLU and ReLU activation functions behave identically when input weights are positive. When input weights are negative, the PReLU function multiplies the weights by a coefficient, a. If a is set to a small, fixed value, the activation function is known as Leaky ReLU (LReLU). The PReLU activation function treats a as a learnable parameter that can be optimized via backpropagation as training progresses. We won’t get into the mathematical details behind how the coefficient a is optimized, but you can read more about it in the paper that originally proposed the PReLU function (Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification, He et al.)
The image below illustrates the difference between the ReLU activation function (left) and the PReLU activation function (right).
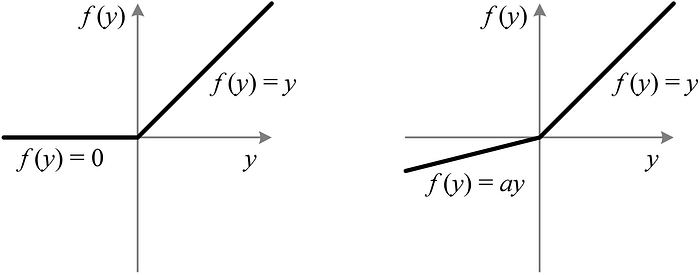
Learning Rate Scheduler
The learning rate is a hyperparameter that controls how much the model weights are adjusted during each pass through a stochastic gradient descent algorithm. Following each pass, the model weights are adjusted by an amount equal to the product of the learning rate and the calculated gradient. If the learning rate is set too high, the algorithm will have difficulty identifying local minima. If the learning rate is set too low, the algorithm will take a very long time to converge on a local minima. As a result, the learning rate is a very important hyperparameter that must be selected carefully to optimize model performance.
Previous work has demonstrated that adjustment of the learning rate during the model training process cam improve model performance. While a larger learning rate value may be useful for identifying the approximate location of a local minima, if it is too large it will prevent the algorithm from converging. One strategy to overcome this challenge is to use a learning rate scheduler to gradually adjust the learning rate as model training progresses.
There are several different types of learning rate schedulers that are commonly used, and you can read more about some of them here. For this problem, we will use a cosine annealing learning rate scheduler. This method was originally proposed in the paper SGDR: Stochastic Gradient Descent with Warm Restarts. Our implementation uses cosine annealing but does not incorporate restarts as proposed by the paper’s authors.
Cosine annealing is used to calculate the learning rate based on the following equations:
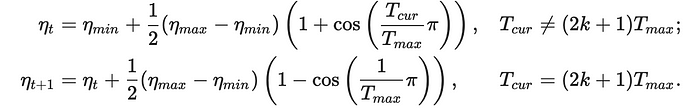
In this equations, ηt represents the learning rate at time step t, ηt+1 represents the learning rate at time step t+1, ηmin represents the minimum learning rate, ηmax represents the maximum learning rate, Tcur represents the current epoch, and Tmax represents the total number of training epochs. The minimum and maximum learning rates as well as the total number of training epochs are set by the user. Using these equations, the learning rate is adjusted dynamically during training.
Model Results
We will evaluate the performance of our model by calculating the average prediction accuracy for each of our ten folds. Based on the recommendation of the dataset creators, we will present the average accuracy across each hold-out fold using a box plot:

The average observed out-of-fold prediction accuracy produced by this model was approximately 79.8%. The table below includes the out-of-fold accuracy for each training fold:

We can see that the model performs better on some folds than others. The highest observed accuracy was for fold5, while the lowest observed accuracy was for fold8.
We also prepared a classification report for each fold using the classification_report function from scikitlearn.metrics. This function calculates the precision, recall, and F1 score for each class within each fold. Reports for each of the ten folds are shown below.

These classification reports help us identify model performance by individual class. We can see that the precision, recall, and F1 score were frequently low across the folds for classes 0 (air_conditioner), 5 (engine_idling), and 7 (jackhammer). However, this trend was not observed across every fold, and each class had at least one strong performing fold. Given that each of these sounds is characterized by repetitive low frequencies, the distance of the source to the recording device may play a significant role in terms of capturing a strong enough signal for our model to be able to correctly classify the sound.
Room for Improvement
Our model performed fairly well, but there are plenty of opportunities for improvement. Further areas of exploration could include:
- Alternative CNN Architectures — We only tested one architecture for our CNN, but researchers have developed a wide variety of different architectures for different types of image classification tasks. The current architecture shows some evidence of overfitting during training, as indicated by the large gap between training and validation loss. Exploring different model architectures will likely provide an opportunity for reduced overfitting and increased prediction accuracy.
- Additional Audio Features — Our model relied solely on Mel spectrograms, but other features generated using the raw audio data as input such as MFCCs may be able to enhance our model’s performance.
- Hyperparameter Tuning — For the most part our CNN and Mel spectrogram generation method utilize default hyperparameters. There are several opportunities for tuning. Experiments may be performed by varying the type of learning rate scheduler, optimizers, and activation functions as well.
- Transfer Learning — There are several pre-trained image classification models that can be used to improve our model’s performance via transfer learning. Examples include ResNet, Inception, VGG, and several others. Using these models requires adapting our image sizes but may produce significant boosts in prediction accuracy.
Thanks For Reading!
Please give this article some claps if you found it helpful! Be sure to check out the Github repository for code examples.
